
정보가 없습니다.
개념 네트워크를 이용한 연상 단어 탐색
- 오일환
- 인천대학교
- 작품구분일반형
- 공개여부공개
- 카테고리정보
- 등록일2017-11-30
- 팀원(공동개발자)BADA2
- 출품 경진대회2017-2학기 아이디어 ‘톡톡’ 캡스톤디자인 산학연계팀 경진대회
- 0
- 0
- 2,492
상세설명
1. 연구의 필요성과 목적
포탈 검색사이트에서 많이 사용하는 연관검색어 기능은 주로 사람들이 많이 함께 검색하는 키워드를 분석하여 관계가 높은 키워드들을 표시해주는 역할을 한다. 따라서 이렇게 함께 검색된 단어들은 어떤 단어에 대한 사람들의 공통 반응 혹은 관심사를 반영한다고 할 수 있다. 따라서 최근 연관검색어를 통해서 트랜드를 분석하는 등의 빅데이터 분석이 많이 이루어지고 있으며, 이러한 단어들을 이용하여 마케팅 등에 이용하고 있다. 그러나 이러한 연관 단어들은 사람들의 반응 혹은 관심사를 반영하고는 있으나, 단어가 주어졌을 때 누구나 연상하기 쉽고, 뻔한 단어라고 생각할 수도 있다.
본 연구과제에서는 어떤 단어에 대해서 사람들이 흔히 생각하기 어렵지만, 조금만 깊이 생각해보면 관련이 있는 단어를 탐색해줄 수 있는 방법에 대해서 연구해 보고자 한다. 우리는 이러한 단어를 연상 단어라고 이름 붙임으로써 기존의 연관 검색어와 구분하고자 한다.
연관 검색어의 경우 사용자 경험(ux)을 기반으로 누적된 데이터를 분석하여 상호 관련이 높은 검색어를 추천해준다면, 연상 단어는 인류가 쌓아온 지식의 총체(백과사전 혹은 문서집합)를 분석하여 관련성이 높은 검색어를 추천해준다.
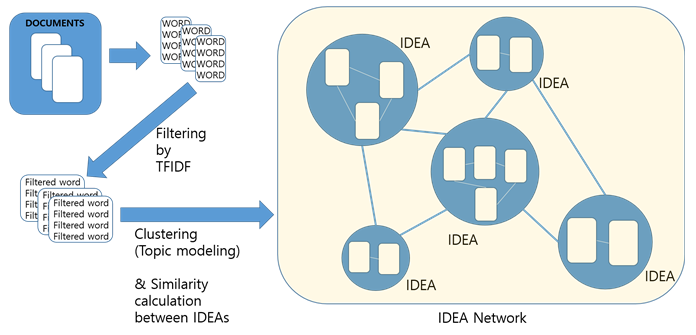
연상 단어의 탐색을 위하여 본 연구에서는 위키피디아 등의 백과사전 사이트에서 문서 데이터를 수집하고, 의미있는 단어를 선정하여 각 문서를 단어의 빈도로 나타내는 방식으로 프리프로세싱한 다. 그 다음 토픽 모델링 혹은 문서 클러스터링의 방법을 통해서 문서들을 주제(Topic) 혹은 개념(Idea) 등으로 나타내고, 이러한 주제 혹은 개념을 노드로 하는 개념 네트워크를 구축할 예정이다. 어떠한 단어가 주어졌을 때, 단어가 속한 주제가 검색되고, 일정한 룰에 의해, 혹은 사용자의 기호(preference)에 의하여 주제와 관련이 높은 또 다른 주제와 그 하위 단어 중 하나 이상이 연상 단어로 추천될 수 있을 것이다.
이러한 연상 단어는 그 활용도가 높을 것이다. 예를 들어 회사의 프로젝트나 아이디어 회의에서 매번 구성인원이 같다면 생각이 비슷하거나 창의적인 아이디어가 나오기 어려운 문제가 있을 수 있다. 창의적인 아이디어는 서로 다른 분야의 개념들이 서로 뒤엉키며 발생할 가능성이 높다. 하지만 같은 분야의 구성원들은 서로 다른 분야의 개념이 뒤섞이기 힘들고 그로인해 비슷한 것들만 생각하게 될 가능성이 높다. 이러한 단점을 인지하지 못하고 회의 중 나온 비슷한 아이디어들 중 하나가 제일 좋은 아이디어 인 것처럼 여겨지게 되기도 한다. 그래서 우리는 연상 단어 검색 기능으로 구성원들이 미처 생각하지 못하는 부분을 일깨워주고 새로운 아이디어가 나올 수 있도록 도와 줄 수 있을 것이다. 아이디어 회의뿐만 아니라 다른 분야에도 실용성 높게 사용할 수 있다. 마케팅에서 연관 검색어 분석은 그 트렌드를 분석하여 소비자에게 구매했던 제품과 비슷한 카테고리의 제품들을 추천하는데 사용한다. 연상 단어는 보다 쉽게 트렌드를 분석 할 수 있고, 뿐만 아니라 소비자의 숨겨진 니즈까지도 파악해 사용자 맞춤 제품 광고를 할 수 있을 것으로 기대한다. 연상 단어 검색 방법을 사용하여 사용자는 포탈 사이트 등에서 자신의 아이디어를 자유롭게 확장시킬 수 있을 것이다. 또한 본 연구과제에서 개발할 연상 단어를 검색하기 위한 방법론은 상품 등의 추천 시스템 등에도 적용 가능할 것이라고 생각되며, 또 다른 결과물인 개념 네트워크 (Idea Network)는 공개화 하여 활용 가치 높은 공공 빅데이터로 활용할 수 있을 것이다.
2. 연구목표 및 독창성
사람들은 연관 검색어와 인기 검색어를 사용 하며 자신이 궁금해 하는 것에 대해서 검색하는 경우가 있다. 하지만 때때로 정말로 알고 싶은 것, 혹은 도움이 되는것은 연관되는 것 뿐 아니라 숨겨진 니즈를 포함한 연상되는 단어일 수 있다. 본 연구과제에서 진행하려는 연구는 브레인스토밍, 마인드 맵과 같은 연상 기법처럼 어떤 단어에서 연상되는 단어를 추천해주는 시스템의 개발이다. 즉, 본 연구 과제의 독창성은 어떤 단어에 대해서 사람들이 흔히 생각하기 어렵지만, 조금만 깊이 생각해보면 관련이 있는 단어를 탐색해줄 수 있는 방법에 있다.
방법상으로, 본 연구과제는 최근 많이 연구 되고 있는 토픽 모델링 기법 및 문서 군집화 기법 등을 이용하여 어떤 코퍼스(Corpus) 에 대해 주제 혹은 개념 네트워크 (Topic or Idea Network)를 만들 수 있는 방법에 대해서 연구하고자 한다. 또한 이러한 네트워크에서 효과적으로 사용자가 만족할 수 있는 연상 단어를 검색하는 방법을 연구하고자 한다.
연상된 단어를 제공 할 수 있다면 사람들은 자신이 알고 싶어 하는 것과 궁금해 하는 것들을 편하고 쉽게 찾을 수 있을 것이며, 특히 자신이 가진 여러 주제의 빅데이터에 적용할 경우 효과적일 수 있다. 예를 들어 경영 데이터를 이용할 경우, 에서 스마트폰과 연관된 내용은 ‘스마트폰 마케팅’, ‘바이럴 마케팅’과 같은 경영관련 단어들이 도출된다. 하지만 같은 단어로 컴퓨터공학 데이터를 이용하면 ‘안드로이드’, ‘application’ 과 같은 기술 중심의 단어들이 연상되어 나올 수 있다.
3. 선행연구 혹은 관련연구
비슷한 주제의 문서들을 묶기 위하여 흔히 문서의 군집화 혹은 클러스터링 (clustering) 방법을 사용할 수 있다 [1-3]. 문서의 군집화는 단어에 등장하는 단어들의 빈도수를 계산하며, 이러한 빈도수 벡터에 대해서 기존의 k-means, 계층적 클러스터링 등 전통적 클러스터링 방법을 적용한다.
토픽 모델링 (Topic Modeling)은 LDA (Latent Dirichlet Allocation) 알고리즘을 기반으로 한 확률 분포 모델을 이용하여 어떠한 토픽을 토픽을 대표하는 단어 및 문서로 나타내기 위한 기법이다 [4]. 토픽 모델링은 더 간단히 말해서 문서의 집합 및 각 문서에 대한 단어들의 빈도수 행렬을 ‘문서 – 토픽’, ‘토픽 – 단어’의 두 행렬로 잘 분해하기 위한 알고리즘이라고 생각할 수 있으며, 어떤 토픽의 집합이라고 가정된 한 문서를 구성하는 단어들을 확률적으로 계산하여 이 결과값을 토픽의 주제어의 집합으로 생각할 수 있다. 이미 토픽 모델링을 이용하여 트위터의 트렌드를 분석하거나, 대선에서 각 후보 별 이슈를 분석하는 등의 연구가 있어 왔다 [5-6]. 또한 최근 딥러닝 (Deep Learning)과 연관되어 공공 의견을 분석하는 연구가 발표된 바 있다 [7].
문서의 클러스터링 혹은 토픽 모델링을 문서 뭉치 (Corpus)에 적용하는데 있어서 문제가 되는 것은 문서의 개수 및 문서를 이루는 단어의 개수이다. 특히, 단어의 경우 모든 단어가 다 문서를 대표하는 성격을 띄지 않으므로, 이러한 단어를 선정하는 것은 연산의 개수를 줄이는 것 뿐 아니라, 분석의 정확도를 높이는데 있어서 큰 기여를 할 수 있다. 문서 뭉치에서 각 문서의 단어들은 그 TF-IDF [8]를 계산함으로써 그 중요도를 측정할 수 있다. 어떤 단어의 TF-IDF는 단어의 빈도수를 나타내는 TF와 단어가 문서 뭉치 내의 얼마나 많은 문서에서 검색되는지를 뜻하는 IDF 값의 곱으로 구해질 수 있다. IDF는 역빈도수라고 하며, 검색되는 문서의 역수로 표현된다. IDF 값은 문서 뭉치의 성격에 따라서 달라질 수 있다. 예를 들어 ‘양자’ 라는 단어는 일반적 문서 뭉치에서는 잘 나오지 않는 단어이므로 높은 IDF 값을 가지나, 과학 및 물리학 관련 문서 뭉치에서는 상투적으로 나오는 단어이므로 낮은 IDF 값을 가진다. 또한 일반적으로 많이 나오는 단어들인 지시어 및 조사, 관사 등등은 TF값은 높지만, 대부분의 경우 극히 낮은 IDF 값을 가지므로 낮은 TF-IDF값을 가지게 되며, 결과적으로 분석에 이용되지 않는다. 일반적으로 TF-IDF는 문서의 분류, 군집화를 비롯한 텍스트 마이닝의 대부분의 연구에 널리 활용된 바 있으며 [9], 심지어는 생물학 데이터의 분석에도 사용 [10]될 만큼 통계적으로 유의미성을 보여주고 있다.
4. 활용성 및 기대효과
본 연구과제의 결과인 연상 단어 탐색 기능은 회사나 연구소의 회의에서 수행하는 brain-storming 등에 이용할 수 있을 것이다. 여러 구성원으로 구성된 조직의 회의에서도, 연상 단어 탐색은 조직 구성원들이 생각하지 못하는 부분을 일깨워주고 새로운 아이디어가 나올 수 있도록 도와 줄 수 있을 것이다. 마케팅 부분에서도 연상 단어는 보다 쉽게 창의적인 아이디어의 창출에 도움울 줄 수 있으리라 예상한다. 또한 사용자는 포탈 사이트 등에서 연상 단어 검색을 이용하여 자신의 아이디어를 자유롭게 확장시킬 수 있을 것이다.
전문적인 연구자들에게도 유용한 툴로 확장할 수 있다. 예를 들어, 자신의 연구를 확장 하거나 관련 연구들을 찾는 경우가 많다. 연구자들은 자신의 연구 키워드를 통하여 자신의 연구와 관련이 있으면서 현재 많이 연구되고 있는 연구 주제들을 접목 시킬 수 있을 것이다. 연상 단어를 검색하기 위한 방법론은 상품 등의 추천 시스템 등에도 적용 가능할 것이다.
연상 단어 탐색 방법론은 논문화 및 특허 출원/등록을 할 예정이며, 이를 이용하여 관련 기업으로의 기술 이전 혹은 창업을 계획하고 있다. 이 경우 사용자의 개인 성향을 파악하여 만족도를 높이는 네트워크 구축 및 탐색 방법의 연구를 향후 연구로 계획하고 있다.
2. 수행기간
구분
연구내용
6월
7월
8월
9월
10월
11월
12월
1월
1
데이터 수집
2
데이터 프리프로세싱
3
문서 군집화
4
개념 네트워크 구축
5
연상 단어의 탐색 방법 개발
6
결과물 품질 측정
7
성과물
(중간) 문서 데이터 및 개념 네트워크
(최종) 연상 단어 탐색 방법론
3. 개발작품 설명
- 1. 연구내용
(1) 데이터의 수집
본 연구에서는 우선적으로 나무위키 (https://namu.wiki) 의 덤프 파일을 사용하여 데이터를 추출한다. 나무위키는 위키피디아보다 공신력은 떨어질 수 있으나, 좀 더 다양한 하위 문화에 관련된 문서를 많이 포함하고 있어 보다 흥미로운 결과를 낼 수 있을 것이라고 예상하기 때문이다. 추후에 위키 페이지 외에도 뉴스 페이지, 논문 아카이브, 사용자 웹페이지 방문목록 등을 이용하여 개념 네트워크를 적용 가능하도록 설계할 예정이다.
(2) 데이터의 프리프로세싱
사이트를 구성하는 각 문서는 그 단어들의 형태소를 분석하여 명사를 찾아낸다. 형태소 분석기로는 KoNLPy [11] 를 사용한다. TF-IDF를 이용하여 찾아낸 명사를 측정하고 일정 이상의 값을 가진 명사만을 분석 대상으로 하고 나머지는 걸러낸다. TF-IDF로 걸러내지 못한 가치 있는 단어를 색출하기 위해 형태소 사전인 Niadic (K-ICT 빅데이터센터)를 이용할 예정이다. 또한 TF-IDF값은 낮지만 가치 있는 단어가 있을수 있다. 이들을 색출하기 위해 구글 (https://google.com) 의 검색 결과를 crawling을 통해 수집하여 가치 있는 명사를 색출할 것 예정이다.
(3) 문서의 군집화
각 문서는 (2)장에서 찾은 단어들의 빈도수의 열벡터로 표현된다. 따라서 우리는 문서를 열로 단어를 행으로 하는 2차원 행렬 데이터를 얻을 수 있다. 이러한 행렬 데이터에 토픽 모델링을 적용함으로써 토픽을 여러 개의 문서 및 단어로 표현할 수 있다. 이를 위해 이미 구현된 Toolkit인 MALLET(http://mallet.cs.umass.edu/topics.php) 혹은 Stanford Topic Modeling Toolbox (https://nlp.stanford.edu/software/tmt/tmt-0.4/)을 사용할 예정이다. 또한 과중한 연산량을 감안하여 하둡 환경에서 연구를 수행할 예정이다.
(4) 개념 네트워크 (Idea Network)의 구축
군집화된 문서는 하나의 토픽 혹은 개념으로 생각할 수 있다. 하나의 토픽이 여러 개의 문서와 단어로 표현 되므로, 우리는 모든 개념 쌍 간의 관계를 문서들의 유사도 및 단어들의 유사도를 통하여 토픽/개념 간의 거리(유사도)를 측정할 수 있다. 일정 기준이상으로 유사도가 높은 토픽들은 간선으로 연결시킨다. 이로써 토픽/개념들의 네트워크를 구축할 수 있다. 이를 개념 네트워크라고 부르며, 네트워크의 각 노드는 문서들의 집합인 토픽/개념이다. 또한 각 노드들은 대표되는 단어를 가질 수 있으며, 노드들을 연결하는 간선에는 상기했듯이 유사도가 부여된다.
(5) 연상 단어의 탐색
사용자가 단어를 입력 하였을 때, 우선 단어에 해당하는 개념을 검색한다. 예를 들어 배라고 검색한다면 타는 배, 먹는 배, 사람의 신체 부위인 배 이렇게 여러 가지 개념이 나타날 수 있다. 우리는 연상 단어를, 검색된 개념 중 하나에서 연결된 다른 개념 노드를 대표하는 단어들이라고 정의할 수 있다. 그림 1의 개념 네트워크의 각 노드(개념)은 문서 혹은 문서를 대표하는 단어를 가질 수 있다. 예제에서 신경망에 대한 연상 단어를 찾기 위해서는 인접한 여러 노드로 이동 가능하다. 이때, 어떤 노드로 이동하게 되는지는 여러 가지 전략이 있을 수 있다. 본 연구과제에서는 랜덤하게 이동 혹은 가중치가 높은 방향으로 이동하는 전략을 계획하고 있다. 그러나 향후에 개개인의 만족도를 높일 수 있는 네트워크 이동 방법을 연구할 예정이다.
4. 활용방안
본 연구과제의 결과인 연상 단어 탐색 기능은 회사나 연구소의 회의에서 수행하는 brain-storming 등에 이용할 수 있을 것이다. 여러 구성원으로 구성된 조직의 회의에서도, 연상 단어 탐색은 조직 구성원들이 생각하지 못하는 부분을 일깨워주고 새로운 아이디어가 나올 수 있도록 도와 줄 수 있을 것이다. 마케팅 부분에서도 연상 단어는 보다 쉽게 창의적인 아이디어의 창출에 도움울 줄 수 있으리라 예상한다. 또한 사용자는 포탈 사이트 등에서 연상 단어 검색을 이용하여 자신의 아이디어를 자유롭게 확장시킬 수 있을 것이다.
전문적인 연구자들에게도 유용한 툴로 확장할 수 있다. 예를 들어, 자신의 연구를 확장하고자 하는 연구자들은 자신의 연구 키워드를 통하여 자신의 연구와 관련이 있으면서 현재 많이 연구되고 있는 연구 주제들을 접목 시킬 수 있을 것이다. 연상 단어를 검색하기 위한 방법론은 상품 등의 추천 시스템등에도 적용 가능할 것이다.
연상 단어 탐색 방법론은 논문화 및 특허 출원/등록을 할 예정이며, 이를 이용하여 관련 기업으로의 기술 이전 혹은 창업을 계획하고 있다. 이 경우 사용자의 개인 성향을 파악하여 만족도를 높이는 네트워크 구축 및 탐색 방법의 연구를 향후 연구로 계획하고 있다.
소개 영상
소개 슬라이드
정보가 없습니다.