
한글폰트 자동생성 모델 개발
- 김예진
- 인천대학교
- 작품구분일반형
- 공개여부공개
- 카테고리정보, 전자
- 등록일2019-01-23
- 팀원(공동개발자)김동언,이상은
- 출품 경진대회현장맞춤형 실전문제연구단 INU-ETRI AI Service Challenge 2차 심사
- 0
- 0
- 4,316
상세설명
1. 수행배경
- 저작권 문제
- 폰트는 저작권과 라이선스가 구분되어 있기 때문에 저작권을 위배하지 않아도 라이선스를 침해하는 경우가 발생할 수 있다.
- 자주 사용하는 '맑은 고딕체', '한컴 윤고딕체'는 유료 폰트이다. 해당 폰트로 만들어진 작업물을 이미지화 하여 모바일 애플리케이션이나 홈페이지등에 적용하면 손해배상 청구를 당할 수 있다.
- 폰트 생성을 위한 높은 비용 문제
- 새로운 폰트를 만드는데에는 전문 디자이너가 4개월 정도의 수작업기간을 필요로 한다.
- 알파벳 몇 개로 이루어진 영어폰트와는 달리 국어사전에 등록된 표준 글자로 폰트를 만드는 경우 글자 2350개가 필요하고 '뙓'과 같이 통용되지 않는 글자까지 고려한다면 1만 1172자가 필요하다.
- 폰트의 다양성 문제
- 시중에 나와있는 한글폰트는 6000여 종이지만 정작 사용되는 폰트는 많지 않다.
- '개성 표현'이 소비자 트렌드의 주요한 특성으로 부상하면서 '나만의 것'에 대한 수요가 증가했다. 이러한 수요는 폰트에 있어서도 동일하게 발생한다. 예로써, 한국저작권위원회는 김훈 소설가의 글씨체를 본 딴 폰트 "KCC-김훈체"를 공유마당에 무료로 공개했다. "나만의 폰트"를 가지는 것은 그 의미가 크다.
- 따라서, 딥러닝 모델로 사용자의 손글씨 특성에 따라 고유한 폰트를 생성함으로써 제작하는 시간이 30분 이내로 줄어들게 되고 저작권 문제를 해결하며 소비자가 원하는 폰트를 쉽게 만들 수 있도록 하여 문제점들을 해결하고자 하였다.
2. 수행기간
주요내용 |
추진일정 |
|||||||||||||||||
| 9월 | 10월 | 11월 | 12월 | ||||||||||||||
1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |||
요구사항 분석 및 설계 |
|
|
|
| ||||||||||||||
템플릿에서 글자 인식 |
|
|
|
| ||||||||||||||
딥러닝 모델 설계 |
|
|
|
| ||||||||||||||
폰트파일 생성 |
|
|
|
| ||||||||||||||
3. 개발작품 설명
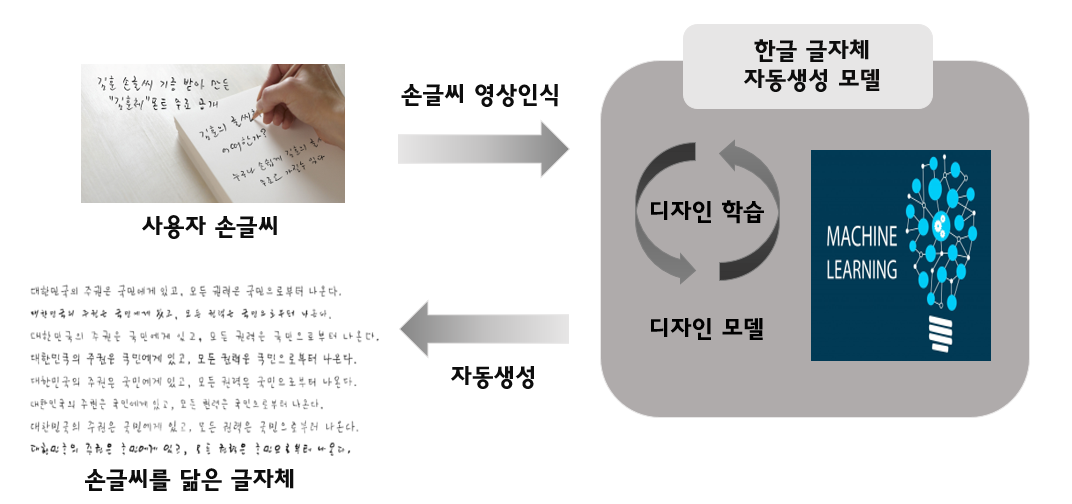
사용자가 템플릿을 다운 받아 정해진 글자를 따라 쓴 뒤 스캔하여 업로드 하면 글자 학습을 위해 오른쪽 그림처럼 그 글자의 유니코드에 맞추어 하나씩 crop하여 이미지를 저장하게 된다.

학습능률을 높이기 위해 글자 크기를 맞추고 중심을 가운데로 옮기는 centering과정을 거친다.

GAN기반의 딥러닝 모델을 사용하여 먼저 Discriminator를 학습시킨 뒤 Gernerator를 학습시켜 글자의 특징을 추출하여 그 특징을 가지고 템플릿에 없는 글자들까지 생성해낸다. 여기서 기존의 encoder에 사용되는 5x5필터대신 dilated convolution filter를 사용하여 더 넓은 범위의 특징점을 효과적으로 추출하도록 하였다.

Gernerator가 생성해낸 글자 png파일을 svg파일로 변환 후, svg파일에서 ttf파일로 변환한다.

딥러닝 기반 폰트파일 생성 결과를 보면 사용자가 템플릿에 썼던 글자와 상당히 유사함을 알 수 있다.

딥러닝 모델로 만들어진 결과물을 실제 워드에 적용한 모습이다. 아래의 사진은 각기 다른 6명의 사용자가 직접 손으로 쓴 글자들이다.

4. 활용방안
- 연구결과물의 산업체 활용방안
- 폰트 자동 생성 모델을 원하는 기업체에 기술 이전 형태로 판매하여 이익을 창출한다.
- 온라인 서비스 제공
- 전용 웹 사이트를 개발하여 폰트 제작을 원하는 소비자들에게 무료로 체험 할 수 있는 기회를 주거나 판매한다.