

A그룹 졸업작품 10. Image2Voice: 이미지에 어울리는 목소리 생성 TTS 웹 서비스
- 위성진
- 인천대학교
- 작품구분일반형
- 공개여부비공개(첨부파일)
- 카테고리웹/앱
- 등록일2024-05-24
- 팀원(공동개발자)위성진, 권효택, 박재현, 방승호
- 출품 경진대회2024년도 컴퓨터공학부 졸업작품발표회
- 0
- 0
- 3,475
상세설명
1. 수행배경
- 최근 많은 관심을 받는 캐릭터 산업에서, 캐릭터의 "목소리"는 소비자들을 더욱 몰입하게 만드는 중요한 요소.
- 하지만, 현 TTS서비스의 불편함들 때문에 Text-to-Speech기술을 다양한 캐릭터 컨텐츠에 활용하는 것이 제한되고 있음
- 기존 TTS서비스들은 따로 reference speech를 준비하거나 사전 생성된 프리셋에서만 음성을 생성할 수 있는 한계가 존재.
- 캐릭터에 어울리는 목소리를 쉽게 생성할 수 있는 Text-to-Speech서비스가 필요.
2. 수행기간
- 2023-09-01 ~2024-05-24
3. 개발작품 설명
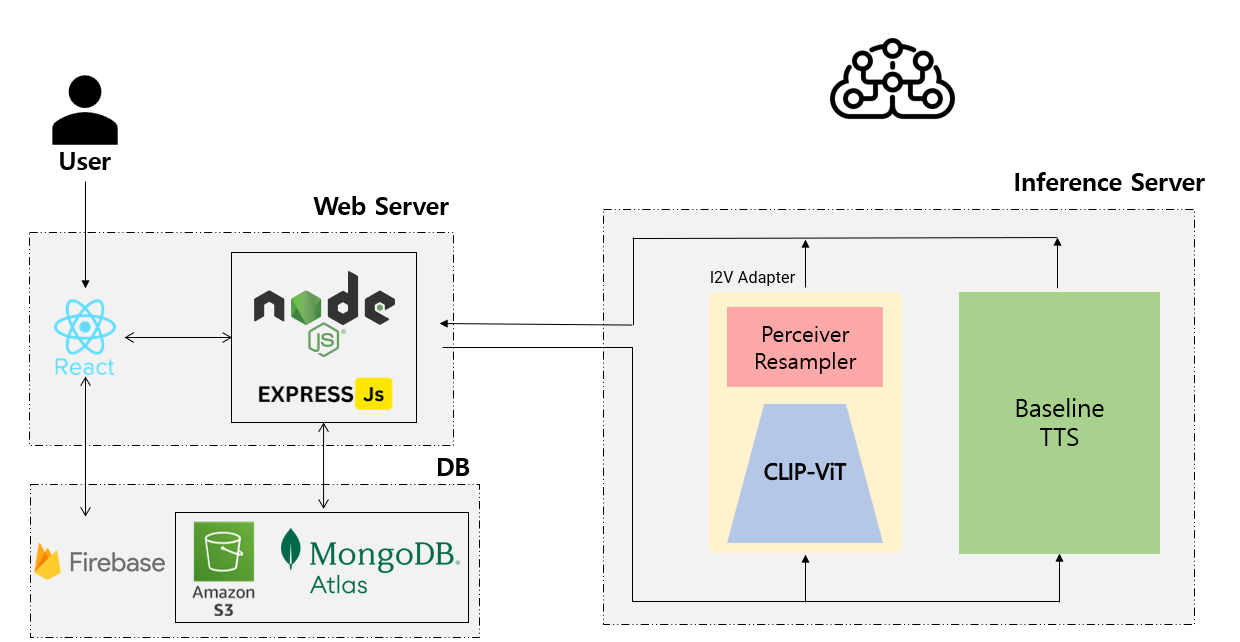
- 캐릭터 이미지를 입력받아 그와 어울리는 목소리로 Text-to-Speech를 수행하는 Multimodal-TTS
- 250여개 캐릭터의 오디오 약 12만샘플, 이미지 약 5400장을 수집
- Automatic Speech Recognition, Speech Emotion Recognition, Image Segmentation 분야의 다양한 오픈소스 인공지능 모델을 활용해 데이터를 전처리, 라벨링, 선별하여 Image-Voice multimodal 데이터셋을 구축.
- Perceiver Resampler 기반 Image-to-Voice Adpater모델을 개발하였고, Pretrained CLIP-ViT와 TTS모델을 함께 활용해 핵심 기능을 구현
- 학습된 모델을 추론서버에 직접 배포하고, React, Node.js를 활용해 사용자가 편리하게 사용할 수 있는 웹서비스를 개발
4. 활용방안
- 게임 개발: 수십~수백개의 캐릭터 각각에게 어울리는 목소리의 음성을 쉽게, 자동으로 부여. 개발 비용 절감.
- 소규모 아티스트: 비용이 부담되는 전문 성우를 고용하지 않고도 자신의 캐릭터에게 딱 맞는 목소리로 음성을 부여. 컨텐츠를 다양화하고 더 많은 채널에서 소비자와 소통
- LLM 챗봇: 챗봇에 부여된 페르소나에 맞게 목소리를 부여하고, 사용자와 직접 대화함으로써 사용자의 몰입감을 증대
소개 영상
소개 슬라이드
기타자료
비공개 자료입니다.